对于吃力的KMP算法,遇到一篇详细的讲解文章和大家分享下:
一:背景

给定一个主字符串(以 S 代替)和模式串(以 P 代替),要求找出 P 在 S 中出现的位置,即串的模式匹配问题。今天来介绍解决这一问题的常用算法之一,Knuth-Morris-Pratt 算法(简称 KMP),这个算法是由高德纳(Donald Ervin Knuth)和沃恩 · 普拉特在 1974 年构思,同年詹姆斯 ·H· 莫里斯也独立地设计出该算法,最终由三人于 1977 年联合发表。
在继续下面的内容之前,有必要在这里介绍下两个概念:前缀和后缀。
由上图所得, “前缀” 指除了最后一个字符以外,一个字符串的全部头部组合;”后缀” 指除了第一个字符以外,一个字符串的全部尾部组合。
二:朴素字符串匹配算法
初遇串的模式匹配问题,我们脑海中的第一反应,必是朴素字符串匹配(暴力匹配),即遍历 S 的每个字符,以该字符为始与 P 比较,全部匹配就输出;否则直到 S 结束。代码如下:
/* 字符串下标始于0 */
int NaiveStringSearch(string S, string P)
{
int i = 0; //S的下标
int j = 0; //P的下标
int s_len = S.size();
int p_len = P.size();
while (i < s_len && j < p_len)
{
if (S[i] == P[j]) //若相等,都前进一步
{
i++;
j++;
}
else //不相等
{
i = i - j + 1;
j = 0;
}
}
if (j == p_len) //匹配成功
return i - j;
return -1;
}
上述算法的时间复杂度为 ,其中 为 S 的长度, 为 P 的长度。这种时间复杂度很难满足我们的需求,接下来进入正题:时间复杂度为 的 KMP 算法。
三:KMP 字符串匹配算法
3.1 算法流程
(1)
首先,主串 “BBC ABCDAB ABCDABCDABDE” 的第一个字符与模式串 “ABCDABD” 的第一个字符,进行比较。因为 B 与 A 不匹配,所以模式串后移一位。
(2)
因为 B 与 A 又不匹配,模式串再往后移。
(3)
就这样,直到主串有一个字符,与模式串的第一个字符相同为止。
(4)
接着比较主串和模式串的下一个字符,还是相同。
(5)
直到主串有一个字符,与模式串对应的字符不相同为止。
(6)
这时,最自然的反应是,将模式串整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把 “搜索位置” 移到已经比较过的位置,重比一遍。
(7)
一个基本事实是,当空格与 D 不匹配时,你其实知道前面六个字符是 “ABCDAB”。KMP 算法的想法是,设法利用这个已知信息,不要把 “搜索位置” 移回已经比较过的位置,而是继续把它向后移,这样就提高了效率。
(8)
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 模式串 | A | B | C | D | A | B | D | '\0' |
| next[j] | -1 | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
(9)
已知空格与 D 不匹配时,前面六个字符 “ABCDAB” 是匹配的。根据跳转数组可知,不匹配处 D 的 next 值为 2,因此接下来从模式串下标为 2 的位置开始匹配。
(10)
因为空格与C不匹配,C 处的 next 值为 0,因此接下来模式串从下标为 0 处开始匹配。
(11)
因为空格与 A 不匹配,此处 next 值为 - 1,表示模式串的第一个字符就不匹配,那么直接往后移一位。
(12)
逐位比较,直到发现 C 与 D 不匹配。于是,下一步从下标为 2 的地方开始匹配。
(13)
逐位比较,直到模式串的最后一位,发现完全匹配,于是搜索完成。
3.2 next 数组是如何求出的
next 数组的求解基于 “前缀” 和“后缀”,即next[j]等于P[0]...P[j-1]最长的相同前后缀的长度(请暂时忽视 j 等于 0 时的情况,下面会有解释)。我们依旧以上述的表格为例,为了方便阅读,我复制在下方了。
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 模式串 | A | B | C | D | A | B | D | '\0' |
| next[j] | -1 | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
/* P为模式串,下标从0开始 */
void GetNext(string P, int next[])
{
int p_len = P.size();
int i = 0; //P的下标
int j = -1; //共有元素长度
next[0] = -1;
while (i < p_len)
{
if (j == -1 || P[i] == P[j])
{
i++;
j++;
next[i] = j;
}
else
j = next[j];
}
}
一脸懵逼,是不是。。。
上述代码是求解每个位置的 next 值,即求解每个位置前面字符串的最长相同前后缀的长度。下面具体分析,我把代码分为 3 部分来讲:
(1)i 的作用是什么?
i 为模式串 P 的下标,从 0 开始,程序中我们依次求出next[i]的值,这很简单。
(2)j 的作用是什么?
从next[i]=j;可以很容易推断出,j 代表前后缀最长共有元素的长度。
(3)if…else… 语句里做了什么?
首先我们必须要明确一个事实:若此时i=3,那我们接下来要求解的便是P[0]...p[3]的最长相同前后缀的长度,也就是next[4],而非next[3],这从下面的代码就可以得到证明:
i++; j++; next[i] = j;
有了这个事实,下面具体分析: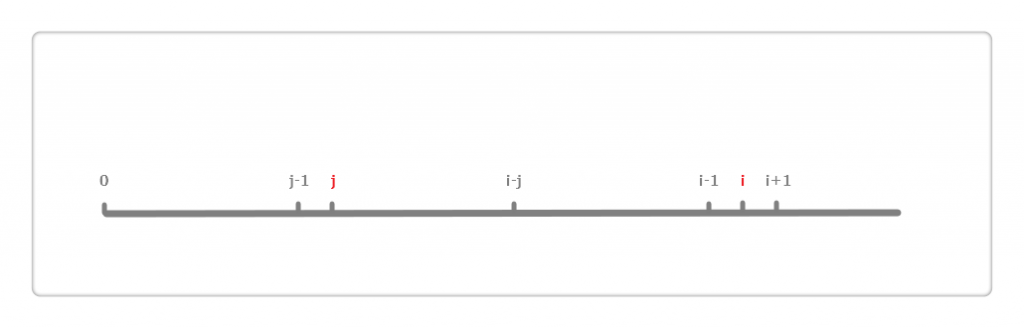
假设 i 和 j 的位置如上图,由next[i]=j得,也就是对于位置 i 来说,区段** 0 到 i-1** 的最长相同前后缀分别是** 0 到 j-1** 和** i-j 到 i-1**,即这两区段内容相同。
按照算法流程,if(P[i]==P[j]),则i++;j++;next[i]=j;;若不等,则j=next[j],见下图:
next[j]的含义是** 0 到 j-1** 区段中最长相同前后缀的长度,如图,用左侧两个椭圆来表示最长相同前后缀,即这两个椭圆代表的区段内容相同;同理,右侧也有相同的两个椭圆。所以 else 语句就是利用第一个椭圆和第四个椭圆内容相同来加快得到** 0 到 i-1** 区段的相同前后缀的长度。
细心的朋友会问 if 语句中j==-1存在的意义是何?第一,程序刚运行时,j 是被初始为 - 1,直接进行P[i]==P[j]判断无疑会报错;第二,else 语句中j=next[j],j 是不断后退的,若 j 在后退中被赋值为 - 1(也就是 j=next[0]),在P[i]==P[j]判断也会报错。综上两点,其意义就是为了特殊边界判断。
四:完整代码
#include<iostream>
#include<string>
using namespace std;
/* P为模式串,下标从0开始 */
void GetNext(string P, int next[])
{
int p_len = P.size();
int i = 0; //P的下标
int j = -1; //共有元素长度
next[0] = -1;
while (i < p_len)
{
if (j == -1 || P[i] == P[j])
{
i++;
j++;
next[i] = j;
}
else
j = next[j];
}
}
/* 在S中找到P第一次出现的位置 */
int KMP(string S, string P, int next[])
{
GetNext(P, next);
int i = 0; //S的下标
int j = 0; //P的下标
int s_len = S.size();
int p_len = P.size();
while (i < s_len && j < p_len)
{
if (j == -1 || S[i] == P[j]) //P的第一个字符不匹配或S[i] == P[j]
{
i++;
j++;
}
else
j = next[j]; //当前字符匹配失败,进行跳转
}
if (j == p_len) //匹配成功
return i - j;
return -1;
}
int main()
{
int next[100] = { 0 };
cout << KMP("bbc abcdab abcdabcdabde", "abcdabd", next) << endl; //15
return 0;
}
五:KMP 优化
| j | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 模式串 | A | B | C | D | A | B | D | '\0' |
| next[j] | -1 | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
/* P为模式串,下标从0开始 */
void GetNextval(string P, int nextval[])
{
int p_len = P.size();
int i = 0; //P的下标
int j = -1; //共有元素长度
nextval[0] = -1;
while (i < p_len)
{
if (j == -1 || P[i] == P[j])
{
i++;
j++;
if (P[i] != P[j])
nextval[i] = j;
else
nextval[i] = nextval[j]; //既然相同就继续往前找前缀
}
else
j = nextval[j];
}
}
在此也给各位读者提个醒,KMP 算法严格来说分为 KMP 算法(未优化版)和 KMP 算法(优化版),所以建议读者在表述 KMP 算法时,最好告知你的版本,因为两者在某些情况下区别很大,这里简单说下。
KMP 算法(未优化版): next 数组表示最长的相同前后缀的长度,我们不仅可以利用 next 来解决模式串的匹配问题,也可以用来解决类似字符串重复问题等等,这类问题大家可以在各大 OJ 找到,这里不作过多表述。
KMP 算法(优化版): 根据代码很容易知道(名称也改为了 nextval),优化后的 next 已不再表示最长的相同前后缀的长度,此时我们利用优化后的 next 可以在模式串匹配问题中以更快的速度得到我们的答案(相较于未优化版)。
转载自KMP算法-刘毅 http://www.61mon.com/index.php/archives/183/
更直白易懂的算法讲解可参考(无算法实现):阮一峰 KMP算法
