这两个都是自己在实际操作上遇到的具体问题,很常见也很实用。MySQL主从复制的需求是因为在将GitHub上一个BitTorrent DHT搜索引擎架设到服务器时,想通过复制实现异步数据同步。而全文索引也是想提高千万数据前提下模糊查询速度,将在之后写出。
主从同步
其中很多都是官方文档中意译过来的,英文文档可能更详细 https://dev.mysql.com/doc/refman/5.7/en/replication-howto.html
一、实现机制
主从同步是在主从复制的基础上个实现的。
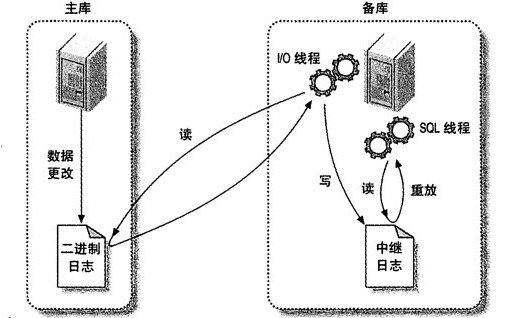
MySQL支持两种复制方式:基于行复制和基于语句复制。但本质上都是通过在主库上记录二进制日志(binlog),然后从库上通过一个I/O线程从主库上读取binlog,然后传输到从库的中继日志中,然后从库的SQL线程从中继日志中读取中继日志,然后应用到从库的数据库中。这样就实现了主从同步。
当然实现A->B->C也是这个道理,只不过C读取的是B的 binlog。
二、配置步骤
1、创建复制帐号
创建单独的复制帐号,主从推荐都加,而权限只需要REPLICATION SLAVE 即可。另外开启MySQL远程连接自然也是必须的。
限制帐号登录IP为slaveip mysql> CREATE USER 'repl'@'slaveip' IDENTIFIED BY 'slavepass'; mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'slaveip';
2、主库配置
主库必须开启二进制日志选项,并指定唯一的 serve-id,在配置文件my.cn或my.ini的[mysqld]部分修改,修改后重启。
[mysqld] log-bin=mysql-bin server-id=1 #binlog-ignore-db=库名 #可选,设置不同步的库,可设置多个 #binlog-do-db=库名 #可选,开启后只同步这些数据库 #expire_logs_days=10 #可选,设置保留时间 #sync_binlog=5 #可选,设置写入频率,以降低性能减少库崩溃损失
server-id 必填,并且取值在1 ~ (2^32)-1,不为0
在复制设置中尽可能使InnoDB事务的持久性和一致性,您可在master my.cnf文件中使用innodb_flush_log_at_trx_commit = 1和sync_binlog = 1。
3、确定主库当前binlog位置
通过命令行在主库开启一个会话,阻止所有表写入操作(确保位置准确)
mysql> FLUSH TABLES WITH READ LOCK; #离开当前会话需再输入,保存效果 mysql> FLUSH TABLES
然后查看当前binlog 文件名(File)和位置(Position),需记住并在之后用到
mysql > SHOW MASTER STATUS; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000003 | 73 | test | manual,mysql | +------------------+----------+--------------+------------------+
在结束第四步后则释放锁
mysql> UNLOCK TABLES;
4、创建数据快照
这是后就有三种情况了:
- 主从库都没有数据,也没有要导入的数据;
- 主从库都没有数据,但有需要导入的数据;
- 主库有存在的数据,但从库是新的空库;
第一种情况可直接跳到下一步,配置从库。
第二种情况也可直接跳到下一步,配置好从库后,将数据导入主库即自动同步到从库。当然也可分别导入主、从库,然后再从头进行主从同步配置。
第三种情况先将主库中数据导出,再导入到从库。
# --master-data 选项可自动追加从库复制过程需要的 CHANGE MASTER TO # 如果不加,则需要主库锁住所有的表 # --ignore-table 排除哪些库 # --databases 指定哪些库 shell> mysqldump --all-databases --master-data > dbdump.db
5、从库配置
从库修改配置,并重启数据库。
[mysqld] server-id=2 #以下为 A->B->C 额外配置 #log-bin=bin #可选,从库开启二进制日志 #relay-log=relay-bin #可选 #log-slave-updates=1 #可选,允许从库将重放的事件也记录到自身的二进制日志中 #read_only=1 # 防止从库被修改
从库启动复制配置
mysql> CHANGE MASTER TO
-> MASTER_HOST='master_host_name',#主库IP
-> MASTER_USER='replication_user_name',#复制帐号
-> MASTER_PASSWORD='replication_password',#密码
-> MASTER_LOG_FILE='recorded_log_file_name',#步骤三的File
-> MASTER_LOG_POS=recorded_log_position;#步骤三的Position
-> MASTER_CONNECT_RETRY=10; #断开重连时间
启动复制,并查看状态
mysql> START SLAVE; #开启同步,结束则为STOP
mysql> SHOW SLAVE STATUS\G
*************************** 1\. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 192.168.0.10
Master_User: repl
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 73
Relay_Log_File: relay-bin.000001
Relay_Log_Pos: 400
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes #
Slave_SQL_Running: Yes #都为yes则正常
...
Seconds_Behind_Master: 0
全文索引
一、前言
个人在实践中遇到的情况是这样的:在InnoDB引擎的一个70万+记录的表中,要模糊查询一个text 类型的字段。常见的like 模糊查询需要消耗1.7 + sec ,已经不让人满意了,更不用说更大量的数据。
二、过程
发现全文索引(FULLTEXT)可能是个不错的办法(当然也可使用一些搜索引擎软件,不过对于几十万量级好像没必要),不过在文档中发现:
1、MySQL是从5.6版本才开始支持InnoDB引擎的全文索引,语法层面上大多数兼容之前MyISAM的全文索引模式。但是不支持中、韩、日文
2、从MySQL 5.7.3开始InnoDB支持全文索引插件,用户可以以Plugin的模式来定义自己的分词规则,或是引入社区开发的全文索引解析器。于是可以使用支持中文的全文索引插件。
3、从MySQL5.7.6版本开始提供了一种内建的全文索引 ngram parser,可以很好的支持CJK字符集(中文、日文、韩文)。内建在代码中,该解析器默认安装,你可以通过指定索引属性(WITH PARSER ngram)来利用该parser。
#创建 mysql> create table ft_test(id int, content text, fulltext (content) with parser ngram); #修改 mysql> alter table ft_test add fulltext content(content) with parser ngram;
当然如果数据量大的话,这可能需要花不少时间(对我可怜的ECS、VPS够呛的)当然这是值得的,通过全文索引能将查询时间降低到0.06 sec 左右。
而N-Gram是使用一种特殊的方式来进行分词,举个简单的例子,假设要对单词’abcd’进行分词,那么其分词结果为:
N=1 : 'a', 'b', 'c', 'd';
N=2 : 'ab', 'bc', 'cd';
N=3 : 'abc','bcd';
N=4: 'abcd';N取决于ngram_token_size的设置,默认值为2。
在执行查询时,用户传递的搜索词也会基于N-Gram进行分解后进行检索。而关于停词和分词处理 可参考官方博文 [http://mysqlserverteam.com/innodb全文索引:n-gram-parser/](http://mysqlserverteam.com/innodb全文索引:n-gram-parser/)
阿里的这篇特性讲解也很详细 http://mysql.taobao.org/monthly/2015/10/01/
